Stony Brook University and Columbia researchers discover that the New York Times word game Connections can serve as a challenging benchmark for training Large Language Models in abstract reasoning.
Stony Brook, NY, Nov 1, 2024 - While AI and machine learning regularly beat the world’s greatest chess players, a recent study found that when it comes to the New York Times Connections, even the best-performing Large Learning Model (LLM), Claude 3.5 Sonnect, can fully solve only 18% of the games.
The study, conducted by Tuhin Chakrabarty, Assistant Professor in the Department of Computer Science at Stony Brook, along with a team of researchers at Columbia, looked at AI’s response to over 400 NYT Connections games. They found that both novice and expert players do better than AI at solving the puzzle.
Here’s how it works:

NYT Connections Game
Players are presented with a 4x4 grid containing 16 words. The task is to group these words into four clusters of four words each, depending on their shared characteristics. For example, in the game above, ‘Followers,’ Sheep,’ ‘Puppets,’ and ‘Lemmings’ form one group, because they can be categorized as ‘Conformists.’
The other three groups are:
- Company ownership offers: Shares, Options, Equity, Stocks
- U.S. cities: Mobile, Buffalo, Billings, Phoenix, and
- What ‘digs’ might mean: Shovels, Likes, Insults, Apartment
Each cluster is harder to identify than the one before.
To group words across proper categories, a player must be able to reason with various forms of knowledge — from Semantic Knowledge (about ‘Conformists’) to Encyclopedic Knowledge (about ‘U.S. cities’).
Tuhin explains the difficulties AI is facing here, “While the task might seem easy to some, many of these words can be easily grouped into several other categories. For example, ‘Likes,’ ‘Followers,’ ‘Shares,’ and ‘Insult’ might be categorized as ‘Social Media Interactions’ at first glance.” These possible groupings become red herrings. The game is designed with this in mind; that’s what makes it more interesting.
The research also found that LLMs are relatively better at reasoning that involves Semantic Relations (‘happy,’ ‘glad,’ ‘joyful’) but they struggle with other types of knowledge, such as Multiword Expressions (‘to kick the bucket’ means ‘to die’) and combined knowledge about Word Form and Word Meaning (adding the prefix ‘un-’ to the verb ‘do’ creates the word ‘undo’ with the opposite meaning).
“We tested five state-of-the-art large language models, namely Google’s Gemini 1.5 Pro, Anthropic’s Claude 3.5 Sonnet, OpenAI’s GPT4 Omni, Meta’s Llama 3.1 405B, and Mistral Large 2 (Mistral-AI, 2024) on 438 NYT Connections games. And we compared the results with human performance on a subset of these games.” The results showed that while all LLMs could partially solve some games, their performance was far from ideal.
To improve Large Language Models’ abstract reasoning capabilities, the team identified and proposed a taxonomy of knowledge that would help AI in grouping words into specific categories.
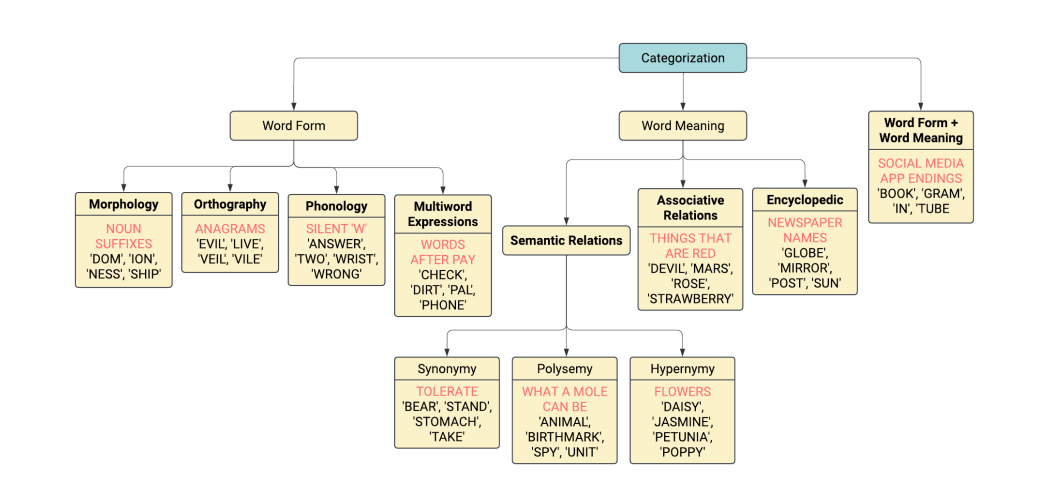
Proposed taxonomy of knowledge types required to solve the Connection games
“Solving the NYT Connections requires a breadth of different knowledge types, which current LLMs do not seem to fully master,” Tuhin said. “Teaching AI to solve this game can serve as a challenging benchmark for training LLMs.”
The team proposes several ways in which this can be accomplished — by generating multiple chains-of-thought reasoning and assigning a higher score to the correct reasoning chain, by allowing LLMs to solve the game one category at a time and incorporating the feedback from humans, or by creating synthetic training data and training the LLMs on this task.
“The hope,” Chakrabarty adds, “is that this will allow us to further close the gap between expert human and LLM performance. Think of all that we might be able to achieve once this becomes possible.”
Communications Assistant
Ankita Nagpal